
기계학습 방법론의 종류
1. Supervised learning (지도 학습)
- 데이터의 input과 output을 아는 상태에서 둘 사이의 관계를 학습하는 것.
2. Unsupervised learning (비지도 학습)
- 데이터의 output을 모르는 상태에서 “interesting structure”를 찾아내는
것.
- Reinforcement learning (강화학습)이 과목에서는 다루지 않음.
Supervised learning (지도 학습)
- Classification (분류) – 각 데이터가 어떤 class에 속하는지 구분 → 카테고리
- Regression (회귀) – 각 데이터가 어떤 continuous variable 에 가까운지 예측 → 연속적
Classification - 각 데이터가 어떤 class에 속하는지 구분

즉 y = ^y가 되도록 ^f을 찾아내는 과정.

Regression - 각 데이터가 어떤 continuous 값에 가까운지 예측

절대값 표시 빠졌음
^f을 고쳐서 min으로 가게 하겠다.
데이터마이닝에서 정확도룰 올리기 위해 -> arg min, arg max
Unsupervised learning (비지도 학습)
- Clustering – 분류기준이 없는 데이터, 어느 집단 (클러스터)에 속하는지 구분 → 카테고리
- Latent factors – 분류 기준이 없는 데이터에서 가장 핵심이 되는 Factor를 추출 (주성분 분석) → (PCA 연속적)

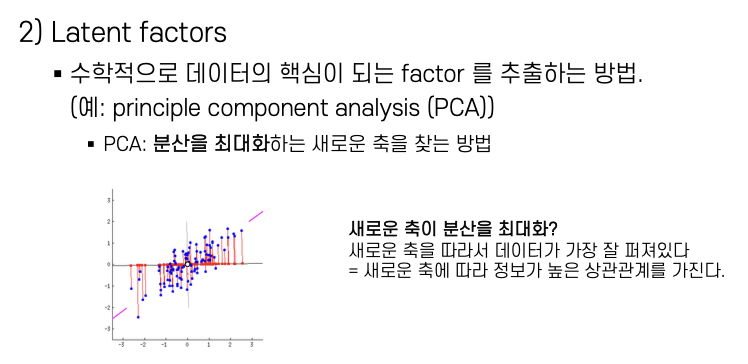
우리가 보는건 대부분 supervised learning
간단한 supervised learning
- 정의
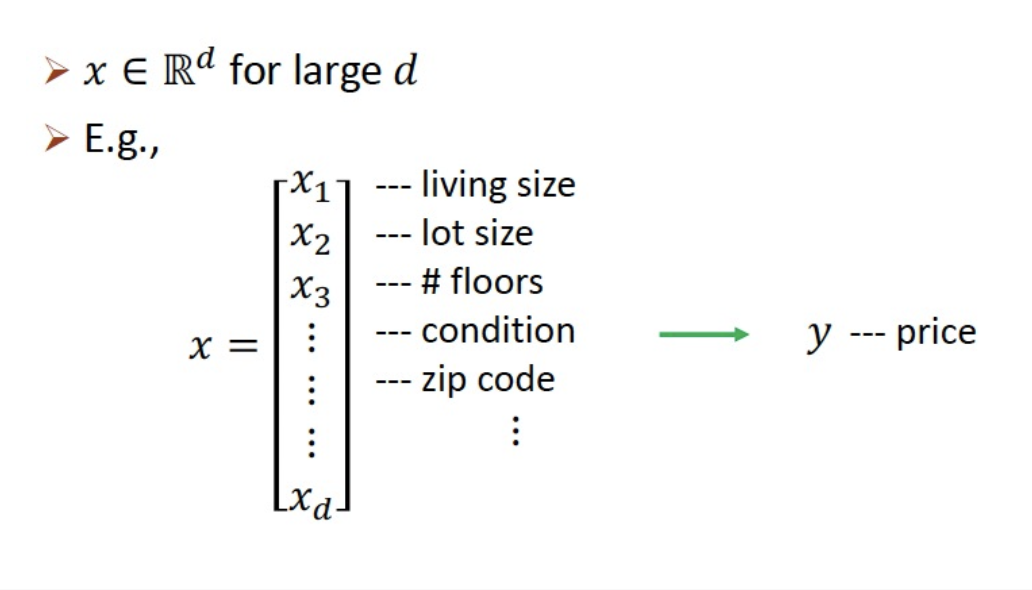
- 즉 입력값 (input data) 𝑥 에 대한 출력값 (정답 레이블) 𝑦 를 맞추도록하는 함수 𝑓: 𝑥 → 𝑦 를 학습하는 것을 supervised learning 지도 학습이라 함

물론 더 많은 입력값을 가질 수 있음.
ex) 몇층인지 컨디션이 어떤지 등등
반응형
'정보통계 > 데이터마이닝' 카테고리의 다른 글
| [데이터마이닝] 임의의 함수에서 최솟값 찾기 (0) | 2024.04.08 |
|---|